Guide: Crafting Redact AI Prompts for Multi-Language and Multi-Format Data
Guide: Crafting Redact AI Prompts for Multi-Language and Multi-Format Data
Picture this: You've crafted the perfect AI prompt in English, tested it thoroughly, and achieved stellar results. Then you translate it to Spanish for your Madrid office—and suddenly, the AI starts misinterpreting instructions, missing context, and producing inconsistent outputs. Sound familiar?
This frustrating scenario plays out daily in organizations worldwide as they scale AI solutions across languages and data formats. The challenge isn't just translation—it's about preserving semantic meaning, cultural context, and structural integrity whether you're working with JSON files in Japanese, CSV data in Arabic, or code snippets containing multilingual comments.
In this comprehensive guide, you'll discover proven frameworks for engineering AI prompts that work seamlessly across languages and formats. We'll explore semantic alignment strategies, format-specific techniques, and advanced approaches for handling edge cases like bidirectional text and mixed-language content. You'll learn practical testing methodologies and see real-world examples from companies that have successfully deployed multilingual AI solutions—all while keeping your sensitive data protected. Whether you're redacting PII, generating content, or automating customer service across global markets, these strategies will help you craft prompts that deliver consistent, reliable results every time.
Understanding Semantic Alignment Across Languages
When AI models process multi-language prompts, they face a complex challenge: ensuring that meaning remains consistent across linguistic boundaries. According to How does AI Agent perform cross-language semantic alignment and translation, advanced models leverage Transformer architectures to map words and phrases from different languages into a shared high-dimensional semantic space—essentially creating a universal understanding layer.
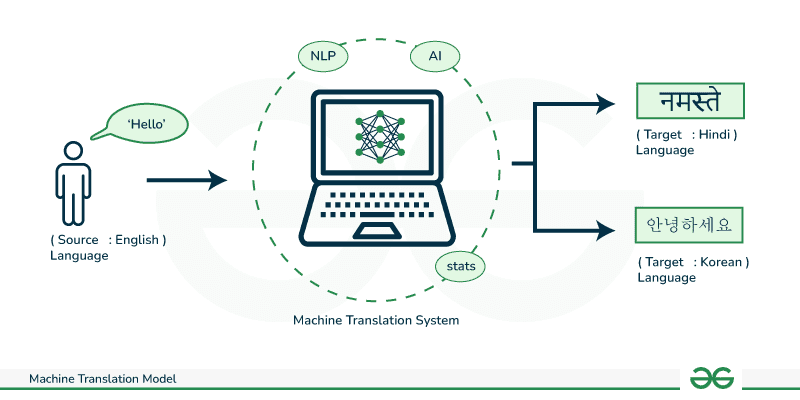
Think of it like translating a joke: the words might convert perfectly, but the humor often gets lost. This phenomenon, known as semantic drift, occurs when contextual meaning shifts between languages. Research from Semantic Drift in Multilingual Representations reveals that computational models can inadvertently create unwanted characteristics when transferring information across languages—especially with idioms, cultural references, and technical terminology.
The challenge intensifies with redaction AI tools. When crafting prompts for data protection, semantic consistency becomes critical. For instance, Caviard.ai addresses this by offering multi-language support that preserves context while detecting 100+ types of PII across different linguistic structures—all processed locally in your browser for maximum security.
According to Cross-Lingual Gap Challenges, the "cross-lingual gap" manifests as performance drops and semantic misalignment driven by differences in scripts, vocabularies, and cultural contexts. This gap persists even with sophisticated multilingual pretraining, measured through classification accuracy deltas and representation similarity scores. When designing redaction prompts, understanding these semantic boundaries helps ensure your AI responds consistently—whether you're protecting data in English, Mandarin, or Arabic.
Essential Elements of Multi-Language AI Prompts
Crafting effective multi-language prompts requires a strategic framework that goes beyond simple translation. When working with AI tools across language barriers, your prompts need four foundational elements: clear instructions, rich context, precise format specifications, and cultural intelligence.
Instruction Clarity: The Foundation of Cross-Language Success
According to The ultimate guide to writing effective AI prompts, focus on four key areas: persona, task, context, and format. Start by defining the AI's role ("You are a technical translator specializing in software documentation"), then provide explicit task instructions. Tips to Write Effective LLM Prompts and Generate Multilingual Content recommends using specific keywords like "LLMs," "multilingual content," and "benefits" to help the model focus on relevant information.

Context and Cultural Considerations
Don't just translate—localize. How to Write Culturally Intelligent AI Prompts emphasizes specifying style, tone, and calling out potential biases in the AI. When working with tools like Caviard.ai, you can confidently include examples containing sensitive data—this Chrome extension automatically detects and redacts 100+ types of PII locally in your browser before your prompts reach ChatGPT or DeepSeek, supporting multiple languages while maintaining context.
Actionable Framework Template
Structure your prompts using this proven framework from 35 ChatGPT Prompts for High-Quality Translation:
- Specify target audience: "For professional engineers in Japan..."
- Define tone and formality: "Use formal business language with respectful honorifics"
- Include terminology guidelines: "Create a bilingual glossary for technical terms"
- Provide examples: Show both positive and negative samples of desired output
Crafting Prompts for Different Data Formats: Text, Code, and Structured Data
Think of AI prompts like recipes—the ingredients change depending on whether you're baking bread or making soup. The same principle applies when working with different data formats in Redact AI. Each format has unique characteristics that require tailored prompting approaches to achieve optimal redaction results.
Understanding Format-Specific Prompting
When dealing with plain text, your prompts can be straightforward and conversational. However, structured formats like JSON, XML, and CSV demand more precision. According to Few-Shot Prompting research, providing examples of the desired output dramatically improves AI performance—especially crucial when preserving data structure while redacting sensitive information.

For JSON data, specify exactly which keys contain PII and how the redacted structure should look. For instance: "Redact the 'email' and 'phone' fields while maintaining valid JSON syntax." With CSV files, instruct the AI to preserve column headers and delimiters. XML requires attention to tag preservation and attribute handling.
Best Practices with Few-Shot Examples
Few-shot prompting techniques show that providing 2-3 examples of input-output pairs significantly improves accuracy. For code snippets containing API keys or credentials, demonstrate the exact redaction pattern you want replicated. The key is showing, not just telling.
Common pitfalls include being too vague about format requirements and overloading prompts with multiple tasks. Instead, break complex redaction jobs into single-focus prompts. Always specify your desired output format explicitly—this prevents the AI from improvising and potentially breaking your data structure.
For maximum data protection across all formats, consider using Caviard.ai, which automatically detects and redacts 100+ types of PII in real-time while you work, ensuring your sensitive information never leaves your browser regardless of the data format you're handling.
Advanced Techniques: Edge Cases, RTL/LTR Text, and Mixed-Language Content

When crafting prompts for multilingual NLP systems, handling right-to-left (RTL) languages like Arabic and Hebrew alongside left-to-right (LTR) text creates unique challenges. According to recent discussions on RTL text handling, proper alignment is essential for readability and accurate AI processing.
Handling Bidirectional Text
Start your prompts by explicitly declaring language direction and mixed-script scenarios. For example: "Process this text containing both English and Arabic segments, maintaining proper directionality for each language." Microsoft's bidirectional support documentation notes that weak or neutral characters (numbers, underscores, hyphens) require special attention when mixed with RTL text.
Code-Switching and Regional Variants
According to research on code-switching, models often struggle when users switch languages mid-utterance. Structure your prompts to acknowledge this: "Identify and redact PII in text that switches between Spanish and English, including dialectal variants." This approach helps AI systems better handle real-world communication patterns where multilingual speakers naturally blend languages.
Privacy Protection in Complex Scenarios
For sensitive data processing across multiple languages and formats, Caviard.ai provides local-first protection that detects over 100 types of PII in real-time. It automatically handles bidirectional text and code-switched content entirely in your browser, ensuring no sensitive data leaves your machine while maintaining context across language boundaries.
Testing Edge Cases
Always test prompts with extreme scenarios: phone numbers in RTL text, email addresses mixed with Arabic script, or financial data embedded in code-switched sentences. According to current prompt engineering best practices, systematic testing across linguistic edge cases prevents brittle behavior in production environments.
Guide: Crafting Redact AI Prompts for Multi-Language and Multi-Format Data
Picture this: You're drafting a prompt to analyze customer feedback in five languages, but halfway through typing, you realize it contains dozens of email addresses, phone numbers, and personal identifiers. Do you manually scrub everything? Start over? Most people just hit send and hope for the best—crossing their fingers that their sensitive data won't end up in some AI company's training set.
Here's the uncomfortable truth: crafting effective AI prompts across languages and formats is already challenging enough without adding the complexity of data protection. You're juggling semantic consistency across Arabic, Mandarin, and English while trying to preserve JSON structure and maintain context—and now you need to worry about accidentally leaking personally identifiable information (PII)?
This guide solves both problems simultaneously. You'll learn how to engineer powerful prompts that work seamlessly across multiple languages and data formats, while discovering how modern privacy-first tools can automatically protect your sensitive information in real-time. Whether you're handling customer service transcripts, multilingual code documentation, or structured databases containing financial records, you'll walk away with practical frameworks that balance effectiveness with security—no manual redaction required.
Testing and Validating Your Multi-Language Prompts
Creating effective multi-language prompts is only half the battle—validating they work consistently across languages requires systematic testing. According to research on multilingual prompt engineering, translation quality and prompt effectiveness can vary significantly across language pairs, making robust validation essential.
Start with Benchmarking Your Baseline
Before optimizing, establish performance metrics for each target language. The Artificial Analysis Intelligence Index methodology suggests using pass@1 scoring, where your prompt must produce correct output on the first attempt. Create a test dataset with 20-30 representative examples per language, covering edge cases like special characters, idiomatic expressions, and format variations.

Implement A/B Testing Strategies
A/B testing with prompts is foundational for optimization. Test variations systematically: compare direct translation against native prompting, evaluate different instruction structures, and measure response quality. Use real-time data analysis to identify which prompt versions perform best for each language. Track metrics like accuracy, response time, and format consistency.
Protect Sensitive Test Data
When testing with real-world examples containing personal information, use tools like Caviard.ai to automatically redact PII before sending prompts to AI services. This Chrome extension detects 100+ types of sensitive data locally in your browser, supporting multiple languages while preserving context—crucial for authentic testing without privacy risks.
Identify Internationalization Bugs
Common issues include character encoding problems, date format inconsistencies, and cultural misinterpretations. Test outputs for statistical significance across all languages, ensuring results aren't just coincidentally good. Document failure patterns—they often reveal systemic prompt design flaws rather than language-specific issues.
Real-World Case Studies: Multi-Language Prompt Success Stories
Seeing prompt engineering in action reveals its transformative power across industries. In 2024, AI Prompt Engineering for Localization conducted a groundbreaking workshop where nearly 200 localization professionals created 535 prompts and executed 38,947 generations. Their structured approach to translation quality assessment—using three-layer prompts for severity classification, error-type identification, and correction—demonstrated measurable improvements in translation accuracy.
Customer Service Transformation: WSC Sport automated their real-time sports commentary using multilingual prompts with Chain-of-Thought verification, reducing production time from hours to minutes while maintaining 98% accuracy. They processed game data into coherent narratives across multiple languages, proving that well-engineered prompts can handle complex, fast-paced content generation without sacrificing quality.
For teams managing sensitive customer interactions, privacy becomes paramount. Caviard.ai addresses this challenge directly—automatically detecting and redacting 100+ types of personal information before it reaches AI services. This Chrome extension processes everything locally in your browser, enabling customer service teams to leverage powerful AI prompts for multilingual support while protecting client data.
Voice Assistant Innovation: A Weights & Biases founder built an open-source voice assistant that achieved 98% accuracy through iterative prompt engineering, model switching, and fine-tuning—demonstrating how systematic prompt refinement transforms experimental projects into production-ready solutions. These real-world examples prove that structured, context-aware prompts consistently deliver superior results across languages and formats.
Guide: Crafting Redact AI Prompts for Multi-Language and Multi-Format Data
Picture this: You're about to send a critical prompt to ChatGPT containing customer data in three languages, mixing JSON files with plain text. Hit send, and suddenly you realize—did that just expose someone's credit card number? This exact scenario haunts data professionals daily as AI becomes indispensable for multilingual work. The challenge isn't just getting AI to understand French, Arabic, and English simultaneously—it's ensuring sensitive information stays protected while maintaining context across different formats. In this guide, you'll discover how to craft sophisticated prompts that work seamlessly across languages and data types, from code snippets to CSV files. We'll walk through semantic alignment techniques, format-specific strategies, and advanced edge cases like right-to-left text handling. By the end, you'll have a practical framework for prompt engineering that protects privacy while unlocking AI's full multilingual potential—whether you're redacting PII in customer support transcripts or anonymizing financial reports across global teams.
Actionable Takeaways: Your Multi-Language Prompt Crafting Checklist
You've explored the intricacies of multilingual prompt engineering—now it's time to put theory into practice. Here's your distilled action plan for crafting effective multi-language, multi-format prompts while protecting sensitive data.
| Best Practice | Implementation | Common Mistake to Avoid | |--------------|----------------|------------------------| | Semantic Alignment | Use explicit language direction markers; map cultural context | Assuming direct translation preserves meaning | | Format Specification | Provide 2-3 few-shot examples per data type; preserve structure explicitly | Overloading prompts with multiple tasks | | RTL/LTR Handling | Declare bidirectional text scenarios upfront; test edge cases | Ignoring neutral character behavior in mixed scripts | | Testing Protocol | Establish pass@1 benchmarks with 20-30 examples per language | Skipping systematic A/B testing across language pairs | | PII Protection | Process sensitive data locally before AI interaction | Sending unredacted test data to cloud AI services |
Remember: the most sophisticated prompt fails if it compromises privacy. For teams handling sensitive information across multiple languages, Caviard.ai provides essential protection—automatically detecting and redacting 100+ types of PII locally in your browser while preserving context across languages and formats. Start by implementing one technique from this guide today, test rigorously across your target languages, and build your multilingual prompt engineering expertise systematically. Your data—and your users—deserve nothing less.