Guide to Crafting Redact AI Prompts for Federated Learning Environments
Guide to Crafting Redact AI Prompts for Federated Learning Environments
Picture this: A healthcare AI that learns from millions of patient records across hundreds of hospitals—yet never sees a single piece of actual patient data. It sounds impossible, right? Welcome to the fascinating world of federated learning, where AI models get smarter while your sensitive information stays exactly where it belongs: locked down on your device.
But here's the catch: traditional prompt engineering falls flat in these distributed environments. When you're working across decentralized systems where privacy isn't just important—it's legally mandated—you need a completely different playbook. One wrong prompt could leak sensitive data across the network, compromise model accuracy, or violate compliance regulations.
This guide cuts through the complexity to show you exactly how to craft prompts that preserve privacy without sacrificing AI performance. Whether you're building federated systems for healthcare, finance, or any privacy-sensitive domain, you'll discover practical frameworks for writing prompts that work across distributed nodes while keeping personal information under lock and key. Let's explore how to make AI collaboration possible without compromising the data that matters most.
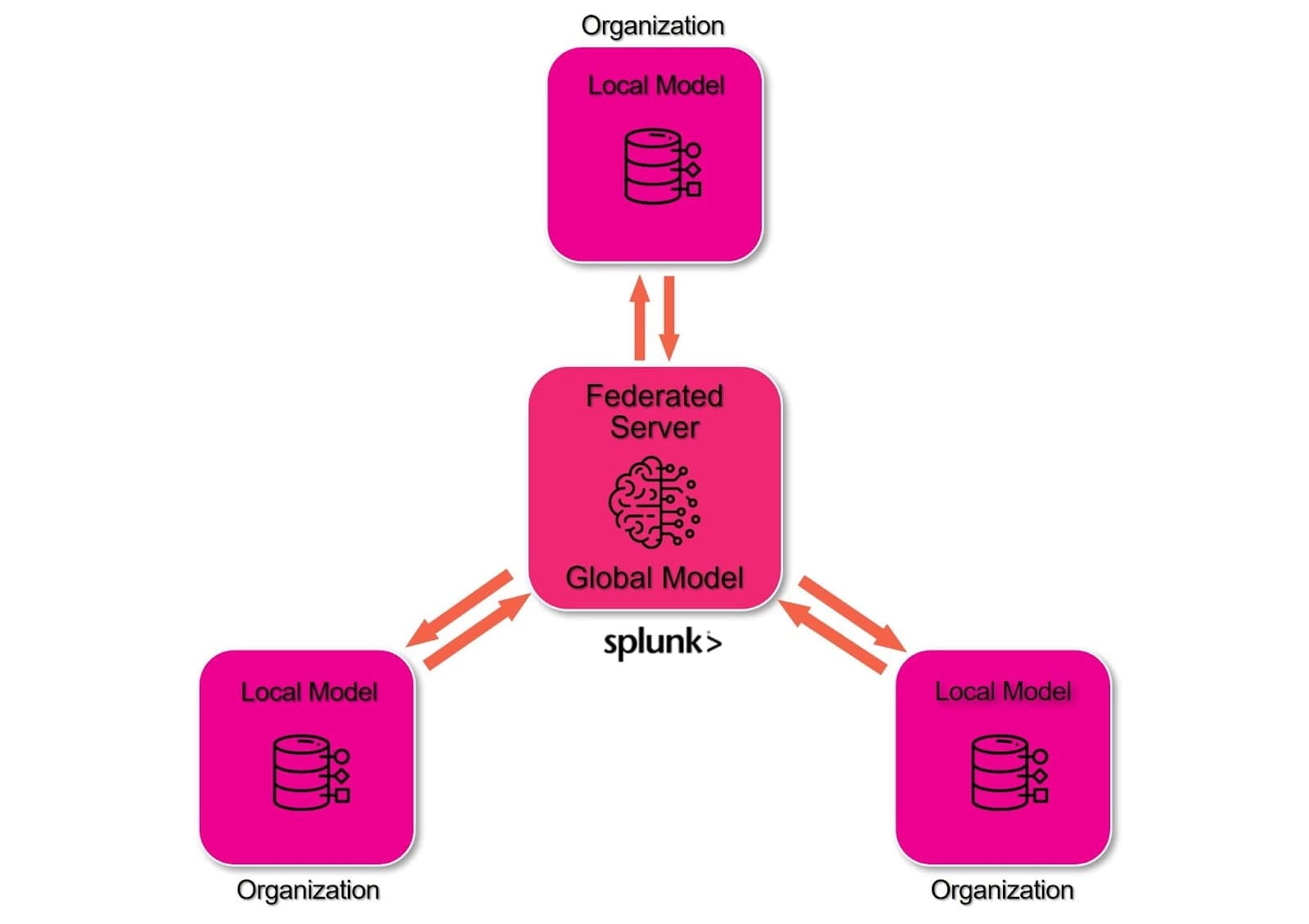
Understanding Federated Learning and Its Unique Prompt Engineering Challenges
Imagine training an AI model across thousands of hospitals without ever sharing patient data. That's the revolutionary promise of federated learning. Unlike traditional centralized machine learning where you collect all data in one place, federated learning trains models across decentralized devices while keeping sensitive information local. Think of it as a collaborative study group where everyone learns from their own notes but shares only the insights.

This decentralized approach creates three distinct challenges for prompt engineering. First, data heterogeneity means each device or organization has different data distributions—your prompts must work across vastly different contexts. According to Nature's research on federated learning challenges, data heterogeneity remains one of the most significant obstacles in FL implementations.
Second, privacy constraints demand that prompts never extract or expose local data. When crafting prompts for federated environments, you're walking a tightrope—extracting insights without revealing sensitive information. This is where tools like Caviard.ai become essential. This Chrome extension automatically redacts personal identifiable information in real-time, detecting over 100 types of sensitive data locally in your browser before it reaches AI services like ChatGPT. It's particularly valuable for federated learning scenarios where privacy preservation is paramount.
Third, communication limitations force you to design concise, efficient prompts. As Sony AI's research demonstrates, federated systems minimize data transmission costs by sharing only model updates. Your prompts must extract maximum value with minimal back-and-forth communication, making every token count in ways traditional centralized approaches never required.
Sources:
- GSC Advanced Research and Reviews - Federated learning fundamentals
- Nature - Federated learning challenges
- Sony AI - Communication efficiency in FL
- Medium - Federated learning overview
The 5 Core Principles of Privacy-Preserving Prompt Engineering
When crafting AI prompts in federated learning environments, protecting sensitive information isn't optional—it's essential. Think of it like preparing food for someone with severe allergies: one slip-up can have serious consequences. Let's break down the five principles that keep your data safe while maintaining AI effectiveness.
Context Minimization: Share Only What Matters
According to Privacy-Preserving Aggregation in Federated Learning, the key is training models "without centralizing sensitive data." In practice, this means stripping prompts down to their bare essentials. Instead of asking "Analyze patient John Smith's diabetes treatment at Memorial Hospital," you'd prompt: "Analyze treatment patterns for type 2 diabetes in urban settings."
The difference? You preserve the analytical value while eliminating identifiable details. This approach works because AI models learn from patterns, not personal stories.
Data Masking Techniques: Your Privacy Shield
Data masking and artificial intelligence involves "obscuring or transforming sensitive information" while keeping data usable for AI training. Modern tools make this seamless—for instance, Caviard.ai automatically detects and redacts over 100 types of personal identifiable information (PII) directly in your browser before prompts reach AI platforms.
Common techniques include substitution (replacing "James Smith" with "Individual A"), redaction (using placeholders like "J______"), and format-preserving encryption for numerical data. The goal is preserving data structure while eliminating identifying markers.
Semantic Preservation: Meaning Without Identity
Here's where art meets science. According to Best Practices for Implementing Privacy-Preserving AI in C# Projects, effective federated systems return "statistical summaries and patterns only" rather than individual records. Your prompts should focus on aggregate insights: "What trends appear in customer purchasing patterns?" instead of "What did customer ID 12345 buy?"
This principle ensures your AI learns valuable insights without memorizing sensitive details. It's like understanding traffic patterns without tracking individual drivers.
Bias Awareness: Fair AI Starts With Fair Prompts
Bias recognition and mitigation strategies emphasize that bias in AI often stems from skewed training data and prompts. When crafting federated learning prompts, actively consider demographic representation. Are you inadvertently asking questions that favor certain groups? Test prompts across diverse data subsets to ensure balanced learning.
For example, rather than "Identify high-performing employees," which might embed historical biases, ask "Identify factors correlating with task completion across all demographic groups." This conscious framing helps AI learn equitable patterns.
Iterative Refinement: Test, Learn, Adapt
Federated In-Context Learning proposes an "iterative, collaborative process" for enhancing AI performance. Apply this to your prompts: start with conservative privacy measures, monitor model performance, and gradually optimize. Track which masked elements impact accuracy and adjust accordingly.
Create a feedback loop where each training round informs your next prompt iteration. Document what works—maybe ZIP codes can be generalized to regions without losing predictive power, while transaction amounts need precision. This evolving approach balances privacy with performance over time.
Step-by-Step Framework: Crafting Effective Redact AI Prompts
Creating privacy-conscious prompts for federated learning requires a structured approach that maintains data utility while protecting sensitive information. Federated learning enables collaborative AI training without centralizing personal data, making redaction strategies essential for success.
Identify Sensitive Data Points
Start by cataloging what personal information your prompts might contain. According to research on privacy-preserving federated learning, protecting individual data while maintaining model performance is crucial. Look for names, addresses, financial details, health records, and location data that could compromise privacy.
For seamless protection, Caviard.ai offers an automated solution that detects over 100 types of sensitive data in real-time. This Chrome extension processes everything locally in your browser, automatically redacting PII before prompts reach AI platforms—perfect for federated learning workflows where privacy is paramount.
Design Context-Preserving Redaction Patterns
Replace sensitive data with meaningful placeholders that maintain semantic value. Instead of "John Smith lives in Boston," use "[PERSON_A] lives in [CITY_1]." This preserves relationships between data points while protecting identity. Advanced prompting techniques emphasize that precise instructions improve AI understanding without exposing raw data.
Test and Validate Your Prompts
Run your redacted prompts through multiple scenarios to verify they produce accurate results. Few-shot prompting works exceptionally well when you need consistent output styles. Test whether your AI model maintains performance when working with masked data versus original inputs, adjusting redaction levels based on accuracy requirements.
Advanced Techniques: Personalization Without Compromising Privacy
Achieving personalization in federated learning environments presents a fascinating paradox: how do you tailor AI responses to individual needs while keeping sensitive data locked down? Recent breakthroughs in client-specific prompt generation and differential privacy integration are proving it's not only possible—it's becoming the gold standard for privacy-conscious AI deployment.
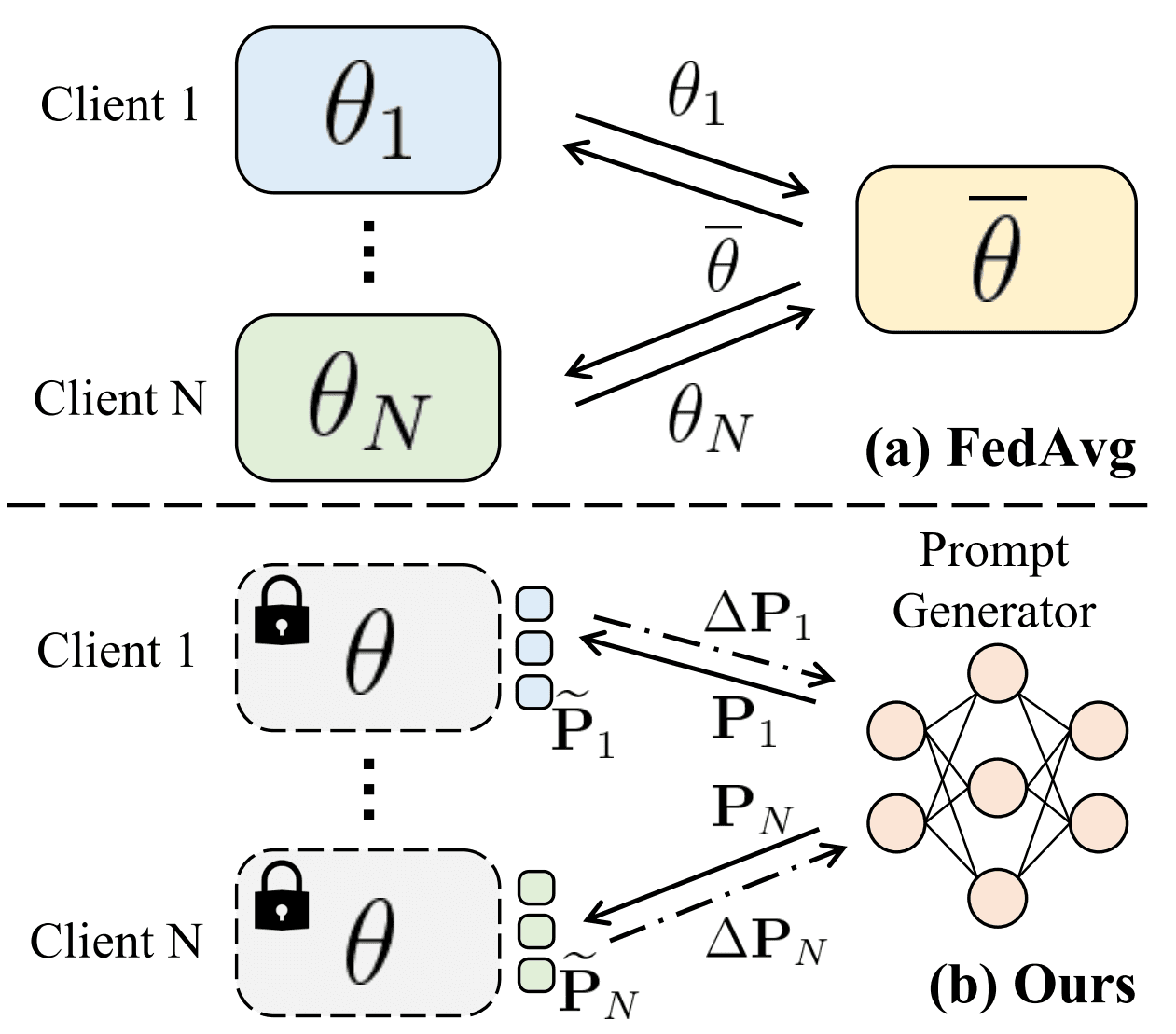
Dual-Prompt Personalization Strategies
Modern frameworks leverage dual-prompt mechanisms that blend global model knowledge with client-specific context. Think of it like having a personal assistant who knows general best practices but adapts to your unique workflow. One organization implementing entropy-adaptive differential privacy achieved 94% accuracy in predictions while maintaining mathematical privacy guarantees—proof that you don't have to sacrifice personalization for security.
Practical Privacy-First Tools
For teams crafting prompts that interact with sensitive data, Caviard.ai represents a breakthrough approach. This Chrome extension automatically redacts over 100 types of PII—names, addresses, credit card numbers—before prompts reach AI platforms like ChatGPT or DeepSeek. What sets it apart is 100% local processing: your data never leaves your browser. You can toggle between original and redacted text instantly, making it ideal for federated learning scenarios where maintaining data sovereignty is non-negotiable while still leveraging powerful foundation models.
The key insight? Real-world federated learning implementations show that keeping data on edge devices while transmitting only essential model updates creates personalized experiences without the privacy trade-offs. As Amazon's research team demonstrates with Alexa devices, collaborative training enables customization while customers retain full data control.
Common Pitfalls and How to Avoid Them

Even experienced developers stumble when crafting redact AI prompts for federated learning. The unique challenges of distributed systems demand heightened attention to detail—one misstep can compromise both model performance and data privacy.
The Over-Redaction Trap
According to Common Prompt Engineering Mistakes: How to Avoid and Fix, the most frequent error is being too vague without specific objectives. In federated settings, this manifests as over-redacting critical context that models need to learn patterns. You might remove so much information that your prompts become meaningless across different nodes. The fix? Test your redacted prompts on sample datasets first—if human readers can't understand the task, neither can your model.
Think of it like giving directions with too many landmarks removed. "Turn at the redacted street near the redacted building" helps nobody. Instead, focus on redacting only genuinely sensitive identifiers while preserving structural context.
Context Loss and Validation Failures
5 Prompt Engineering Mistakes That Cost Me Accuracy highlights how ambiguous instructions directly reduce model accuracy. In federated environments, insufficient context testing across multiple data distributions compounds this problem. Each participating node might interpret your prompt differently, leading to inconsistent model updates.
Your safety net? Implement robust validation techniques from AI Prompt Testing in 2025: Tools, Methods & Best Practices—start with 50-100 test cases per node, scaling to hundreds for production systems. Deploy monitoring tools like Caviard.ai, which locally detects 100+ types of sensitive data in real-time, ensuring your redaction strategy maintains both privacy and prompt effectiveness without sending data off-device.
Source Citations:
- Common Prompt Engineering Mistakes
- 5 Prompt Engineering Mistakes
- AI Prompt Testing Guide
- Caviard.ai Privacy Tool
Caviard.ai: Automated PII Protection for AI Prompts
Picture this: You're crafting prompts for a federated learning system when you realize your test data contains customer names, credit card numbers, and addresses. Manual redaction would take hours—and you'd still miss things. This exact challenge drove the development of Caviard.ai, a Chrome extension that's changing how practitioners protect privacy in AI workflows.
What makes Caviard revolutionary for federated learning environments is its 100% local processing architecture. Every bit of detection and masking happens directly in your browser before prompts reach ChatGPT, DeepSeek, or other AI platforms. Your sensitive data never leaves your machine—a critical requirement when working with distributed datasets across multiple nodes.
The tool automatically identifies over 100 types of PII in real-time as you type, from obvious identifiers like "James Smith" and "4782-5510-3267-8901" to subtle data points like email addresses and location coordinates. Advanced regex patterns and algorithms preserve the original context and format while masking sensitive information—so your prompts maintain their semantic value for model training.
The toggle feature proves invaluable during federated learning workflows. Hit a keyboard shortcut to instantly switch between original and redacted text, verifying your prompts maintain enough context for accurate model updates while protecting individual privacy. You can also create customizable rules for organization-specific data types, adapting the extension to your unique federated environment.
For practitioners balancing the dual demands of personalization and privacy, Caviard seamlessly integrates into existing prompt engineering workflows without requiring changes to your infrastructure or data pipelines. It's the practical solution for ensuring your federated learning prompts meet stringent privacy standards while maintaining the utility needed for effective model training.
Measuring Success: Validation and Performance Metrics
Evaluating privacy-preserving prompts in federated learning requires a multi-dimensional approach that balances security with functionality. Think of it like measuring a car's performance—you need to track speed, fuel efficiency, and safety simultaneously to get the complete picture.
Privacy Leakage Assessment forms the foundation of your evaluation framework. According to PRIFLEX: A Secure Federated Learning Framework, comprehensive frameworks now exist specifically for evaluating privacy leakage in cross-modal data environments. The FEDLAD Framework provides standardized benchmarks for testing how well your prompts resist deep leakage attacks, giving you quantifiable privacy scores before deployment.

Key metrics to track include:
- Model accuracy degradation (target: <5% loss compared to non-private baselines)
- Communication efficiency measured in bandwidth reduction
- Personalization effectiveness across diverse client datasets
Research on Privacy-Preserving Machine Learning in Financial Customer Data demonstrates that you can maintain 90%+ accuracy while preserving privacy through careful prompt engineering. For real-time protection at the client level, tools like Caviard.ai offer immediate PII detection and redaction directly in your browser, processing 100+ types of sensitive data locally before prompts reach AI services.
Continuous monitoring through communication-efficient verification schemes ensures your privacy guarantees hold throughout the learning process. Set up automated alerts when privacy budgets approach thresholds, and conduct quarterly audits using standardized frameworks to maintain optimal performance.
Practical Takeaways and Implementation Checklist
Ready to build privacy-first AI prompts? Start by auditing your current prompts for PII exposure—names, locations, financial data—and establish baseline privacy metrics before making changes. Create a template library with pre-approved redaction patterns for common scenarios, making it easier for teams to maintain consistency across federated nodes.
Your Implementation Checklist:
| Phase | Action | Success Metric | |-------|--------|----------------| | Setup | Install automated PII detection tools | 100% local processing confirmed | | Design | Create context-preserving placeholders | Semantic meaning retained | | Testing | Validate across 50+ test cases per node | <5% accuracy degradation | | Monitoring | Track privacy leakage continuously | Zero data breaches maintained |
The beauty of federated learning lies in its collaborative power without centralized risk. By following these principles—context minimization, strategic masking, semantic preservation—you're not just protecting data; you're building trust with every prompt you craft.
Caviard.ai takes the guesswork out of PII protection by automatically detecting and redacting over 100 types of sensitive data directly in your browser before prompts reach AI platforms. It's like having a privacy guardian that works invisibly, letting you focus on crafting effective prompts instead of manually hunting for data leaks.
Start small, test rigorously, and iterate based on real performance data. Your federated learning system will thank you with robust models that respect privacy boundaries while delivering personalized insights.